Chapter 02
That story about sending letters.
It was 2009. The financial crisis had hit and an insurance company was looking for ways to deal with the situation. There wasn’t a budget left to do propoer television campaigns, so people were scrambling for good ideas on the margin. Luckily, there was one manager who spotted a potential “win.”
The company had made a lot of investments in its data warehouse in the past few years and the manager realized that some of the customer data in this warehouse could be used to predict who might default on a payment. It helps to remember that this was a few years before the big data bubble so this idea was honestly relatively novel.
Defaults are a huge pain to deal with, because it quickly turns into a large legal expense when the defaulting party suddenly needs the insurance to take place. So if they could reach out to folks just before they would default, they might be able to save a lot of time and money. The manager made a pitch and got the green light to go and implement it.
Predicting the defaults turned out to be relatively easy. They didn’t even need to consider a machine learning model; they could just implement it as a database query. The trick was not to predict when a user would default but instead to try and predict who was safe. This may sound counter intuitive but this was a period where the risk of defaulting on payment so high in some of their portfolios that it was easier to exclude the folks who seemed perfectly safe. It also helps to remember the business case; the cost of a legal battle as the result of a default is incredibly high. So anything that can make even a small dent in that is a big win.
It suprised everyone, but a couple of domain-specific rules really did the trick. The team back-tested their approach on historical data and did some back-of-the-letter mathematics to figure out how expensive it might be to do outreach.
The conclusion of the exercise: they were on to something.
While the data analysts were tuning the final details of their approach, the manager started thinking about the best way to approach their customers. They briefly contemplated calling people, but the sheer volume would make that a costly endeavor. Instead, they opted to send a letter. The letter would ask the users if they needed help during the financial crises and that a revised payment plan was ready for them if they needed it. Sending a letter also made the legal team happy because it could be seen as an act of proactive engagement.
Sending a considerable volume of letters reqquires preparation, but the team had all the information they need. They had been given access to the central customer database which contained a table with all the available client information. This table included a complete address and could be linked to past payment information. That allowed them to apply their heuristic, select the relevant users, generate a letter with a template and automatically print the envelopes to be sent out. The team also went the extra mile by also making a cost-benefit analysis that compared the cost of sending a letter to the potential savings per account.
With the deadline looming, they quickly learned that the data processing wouldn’t be the hard part. The tricky thing was that they needed to send many thousands of letters. That meant that they had to arrange for a small printshop to buckle up as well as a delivery van to pick up the letters from the press to their postal partner. This was no impossible task, but it did require a bit of last-minute maneuvering to get the letters sent out on time.
Despite all this, they managed to get the letters sent. The letters were printed and shipped on a Thursday, which meant that the team had a well-deserved celebration on Friday after. Despite the financial crisis, senior management was happy to see that one team still got to try out new data-driven approaches to their business. During a financial crisis, it is certainly nice to be able to win one.
But then came the following week.
The following Monday, two postal service employees had driven their truck to the company headquarters to deliver thousands of letters all addressed to the headquarters. This was very strange because none of the many thousands of letters had names of actual employees. You can imagine the facial expression of the frontdesk staff when the serviceman dropped a small pallet of letters in their hallway. It really took them a while to figure out who to call about this. Eventually, by the end of a very long and confusing day, it became clear that these letters were part of the aforementioned project.
All of these had the address and postal code of the headquarters but all the letters had the names of clients who were supposed to get a pro-active warning.
Something had gone wrong.

When the team got together to debrief the first thought that went through everyone’s mind was that something must have gone wrong with the templates. Maybe they accidentally hard-coded the address? The team started double-checking. About 32% of all sent letters had bounced back to HQ, and they needed an explanation.
It … didn’t stop there though.
The day after, another postal truck arrived with even more letters. Another 8% of all the letters seemed to have bounced back now, and it became adequately frustrating for the team. They double-checked their logs. They triple-checked their database queries. They even checked their templates for the fourth time. They didn’t find a single mistake. You could hear the senior programmers mumble the same thing all day; "How could there be a mistake? We wrote unit tests for this!".
It took a week before the team took a step back and started thinking about the bigger picture. Maybe the issue wasn’t in anything that the team produced but rather something they relied on?
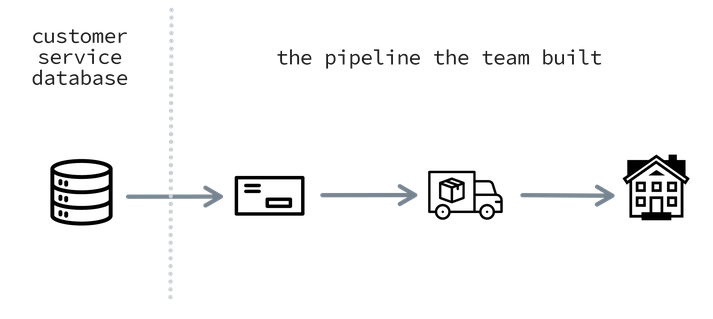
The team started checking the customer service database. And sure enough, they began seeing issues. It confirmed that a big chunk of all the active users had the same address and postal code as the company HQ. But why?
If only they had taken the effort of talking to a customer service employee, then they would’ve gladly explained that the database came with a particular configuration. It was set up in such a way that there was no way to add a customer to the system without an adress attached that was confirmed to exist. In technical terms, the address column wasn’t allowed to have a NULL value. Any change to the database that did not meet this constraint would be refused. This strict rule was implemented after the tech leadership attended a conference where they heard this was a best-practice for data quality.
As such, the engineers in charge of maintaining the database didn’t want to change this setting because they had a hard rule for non-nullable fields on all their tables.

Given these stubborn engineers, the customer service team needed to get creative. Sometimes, the customer support team would receive a letter returned to the sender because the client no longer lived at the current address. Because of the way that the database was configured, they couldn’t set the address to “empty” without removing the entire record. This was a huge nuisance, because internally they needed some way to indicate that the address was unknown.
And this is how, as is often the case, the customer support group resorted to a convention. Whenever they had a report of a letter that bounced, they would simply set the field to the headquarters’ address. That way, at least within the team, they could look at a database entry and immediately know ahead of time that the user would not reply to a letter if one were sent. Not all, but some of the other teams also knew about this convention, which was great because this way everyone could go on with their short-term objectives.

Appendix
This was a story about sending letters. But it was also a story about how data and knowledge are two different things. In large companies data usually gets embedded in a database while knowledge often gets embedded in the minds of people, most of whom are not in your team.
There are two lessons that could be drawn from this story though. When you’re rolling out something big, even when there’s a deadline, it helps to do two things.
-
First, if you’re dealing with a large userbase, maybe don’t roll out a new feature to all of your intended users without some sort of "abort" button. Even better: you probably want to roll it out on a small random subset first. That way, any mistakes will have a much smaller impact and you might still have time to steer the approach.
-
Second, perhaps more importantly, before using a dataset from another team, you probably want to confirm that you can trust the data. This is especially true if you organization is large and complex. In these places, assumptions aren’t your friend. If you're responsible for a project, you also have to carry some responsibility on what you build on top of. It does not take a very long time to run some sanity checks on the database, like checking for duplicates or missing values. If these exist, you might want to ask the team that maintains the database about it.